約2年ぶりにディスクのトラブルが発生したのでその対応について書きたいと思います。
ここ2週間ファイルサーバーへのファイルコピーの転送速度が40%程度遅くなっていたのでおかしいなと思い、CentOSのGUIにあるディスクユーティリティを起動してsmart情報を確認しました。案の定、2個のディスクの代替処理済みセクタが存在していました。
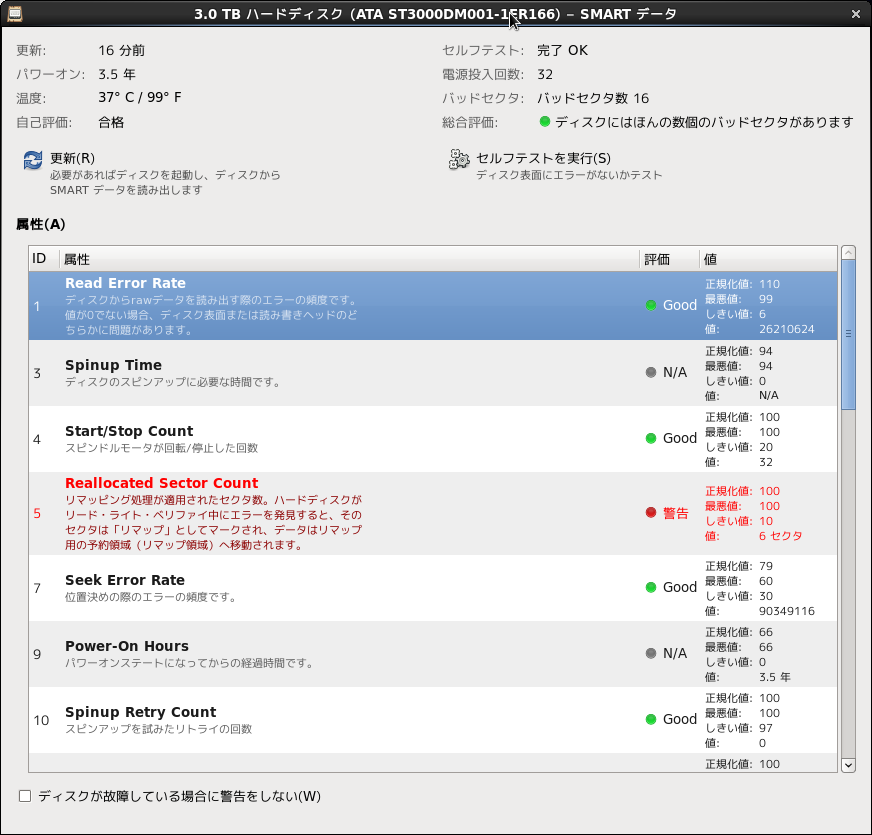
なお、以前にも紹介しましたが自宅のファイルサーバーは4+2のRAID6で構成されていて、ディスク構成は以下のようになっています。
ST3000DM001-1ER166
ST3000DM001-1ER166
ST3000DM001-1ER166
ST3000DM001-1ER166
MG03ACA300
ST3000DM008-2DM166
1個が東芝製である以外、見事にSeagate製です。これは別に私がSeagate信者というわけではなく単にRMA(Return Merchandise Authorization:返品保証)送付先が国内にあるからという理由です。2年前ぐらいまではWestern DigitalのRMA送付先は海外だったので面倒くさかったのです。
LinuxのSoft RAID(md)は構成されているRAIDに新たにディスクを追加するとホットスペアと認識されるので以下の作業を繰り返して、悪いディスクを取り除こうと思います。
(1)ディスクを追加する
(2)スペアパーティションにデータをコピーする
(3)悪いディスクを取り除く
仮にディスクが既に認識されないというような状態だと(2)マニュアルではなく自動で処理されます。
とりあえず、手元にはRMAでSeagateから送られてきたリファービッシュ(再生品)のディスクが1個あるので、まずはこれを使って上記の流れをなぞってみたいと思います。
(1)ディスクを追加する
①サーバーの電源を落としてディスクを追加します。

交換用HDDにリムーバブルトレイを装着したところ

ファイルサーバーに使用しているケースはHDD用リムーバブルスロットが7スロットあるのでディスク交換も簡単。
ディスクを追加してサーバーを起動すると2つのRAIDパーティションの1つが既に縮退状態になっていました。RAID状態の確認にはcat /proc/mdstatを使用します。
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md126 : active raid6 sdb2[2] sdd2[5] sdg2[6] sde2[3] sdf2[4]
3906483968 blocks super 1.2 level 6, 64k chunk, algorithm 2 [6/5] [U_UUUU]
bitmap: 2/8 pages [8KB], 65536KB chunkmd127 : active raid6 sdh1[10] sdb1[6] sdd1[7] sdg1[11] sde1[9] sdf1[8]
7814049792 blocks super 1.2 level 6, 256k chunk, algorithm 2 [6/6] [UUUUUU]
赤字の部分と青地の部分を比べればわかりますが赤字の方はパーティションが1つ足りません。RAIDサービス起動時に該当ディスクのパーティション情報を読み込めなかったと考えられます。
②既存のディスクとパーティション構成を同一にする
2TB以上の大きさのディスクを使用するのでpartedコマンドを使用します。
# parted /dev/sdc
ーー parted デバイスファイル で対象デバイスを指定できます。ーー
GNU Parted 2.1
/dev/sdc を使用
GNU Parted へようこそ! コマンド一覧を見るには ‘help’ と入力してください。
(parted) p
モデル: ATA ST3000DM001-1ER1 (scsi)
ディスク /dev/sdc: 3001GB
セクタサイズ (論理/物理): 512B/4096B
パーティションテーブル: gpt
番号 開始 終了 サイズ ファイルシステム 名前 フラグーー pコマンドでディスクおよびパーティション情報を確認しています。今回は一度Windowsで使用したディスクを流用しているのでパーティション情報が一部残っていますが、新品ではパーティションテーブル情報はありません。ーー
(parted) mklabel gpt
ーー パーティションテーブルを作成します。2TB以上ではgptを選びます。ーー
警告: いま存在している /dev/sdc のディスクラベルは破壊され、このディスクの全データが失われます。続行しますか?
はい(Y)/Yes/いいえ(N)/No? yset
(parted) unit sーー 作成するパーティションの容量を指定する単位を決めます。ここではセクターを単位として指定します。ーー
(parted) mkpart
ーー パーティション作成はmkpartコマンドです。ーー
パーティションの名前? []? primary
ーー gptでは単に名前なので何を入れてもかまいません。MBR時代の名残りでついついprimaryと入れているだけです。ーー
ファイルシステムの種類? [ext2]?
ーー RAIDで使用するのであまり意味はありません。デフォルトままリターンキーを押します。ーー
開始? 2048s
終了? 3907028991sーー 作成するパーティションの開始セクターと終了セクターを指定します。ここは大変重要でRAIDを構成する他のディスクに合わせる必要があります。ーー
(parted) mkpart
パーティションの名前? []? primary
ファイルシステムの種類? [ext2]?
開始? 3907028992s
終了? 5860533134sーー このディスクは2つパーティションを作成しているので同じことをもう一度繰り返します。ーー
(parted) set 1 raid on
(parted) set 2 raid onーー RAIDで使用するのでraidというフラグを立てます。ーー
(parted) p
モデル: ATA ST3000DM001-1ER1 (scsi)
ディスク /dev/sdc: 5860533168s
セクタサイズ (論理/物理): 512B/4096B
パーティションテーブル: gpt番号 開始 終了 サイズ ファイルシステム 名前 フラグ
1 2048s 3907028991s 3907026944s primary raid
2 3907028992s 5860533134s 1953504143s primary raidーー pコマンドで作成したパーティションを確認します。ーー
③作成したパーティションをRAIDに追加する
Soft RAIDに関するオペレーションはmdadmコマンドを使用します。mdadmコマンドは非常に多機能なのでmdadmコマンドの使用方法について詳しく知りたい方はググってください(笑)。
[root@lhasa ~]# mdadm –manage /dev/md127 –add /dev/sdc1
mdadm: added /dev/sdc1–「RAIDパーティション/dev/md127に/dev/sdc1を追加する」というオペレーションです。ここではまず、問題がない方のパーティションを追加しています。ーー
[root@lhasa ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md126 : active raid6 sdb2[2] sdd2[5] sdg2[6] sde2[3] sdf2[4]
3906483968 blocks super 1.2 level 6, 64k chunk, algorithm 2 [6/5] [U_UUUU]
bitmap: 2/8 pages [8KB], 65536KB chunkmd127 : active raid6 sdc1[12](S) sdh1[10] sdb1[6] sdd1[7] sdg1[11] sde1[9] sdf1[8]
7814049792 blocks super 1.2 level 6, 256k chunk, algorithm 2 [6/6] [UUUUUU]-- sdc1[12](S)の”S”はスペアを表します。ーー
次に欠けているRAIDパーティションにパーティションを追加します。
[root@lhasa ~]# mdadm –manage /dev/md126 –add /dev/sdc2
mdadm: added /dev/sdc2[root@lhasa ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md126 : active raid6 sdc2[7] sdb2[2] sdd2[5] sdg2[6] sde2[3] sdf2[4]
3906483968 blocks super 1.2 level 6, 64k chunk, algorithm 2 [6/5] [U_UUUU]
[>………………..] recovery = 0.3% (3900096/976620992) finish=232.4min speed=69734K/sec
bitmap: 2/8 pages [8KB], 65536KB chunkーー パーティションを追加すると直ちにリビルドが開始されることが確認できます。ーー
(2)スペアパーティションにデータをコピーする
まだ認識しているパーティションをスペアパーティションにコピーするためにはreplaceオプションを使用します。これは元のパーティションを生かしたまま新パーティションにデータをコピーします。この動作により、処理中に他のディスクで問題が発生しても影響を最小化することができるとともにリビルドに比べて処理のスピードアップが期待できます。
[root@lhasa ~]# mdadm –manage /dev/md127 –replace /dev/sdh1
mdadm: Marked /dev/sdh1 (device 0 in /dev/md127) for replacementーー 交換対象(コピー元)のデバイスを指定します。ーー
[root@lhasa ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md126 : active raid6 sdc2[7] sdb2[2] sdd2[5] sdg2[6] sde2[3] sdf2[4]
3906483968 blocks super 1.2 level 6, 64k chunk, algorithm 2 [6/6] [UUUUUU]
bitmap: 0/8 pages [0KB], 65536KB chunkmd127 : active raid6 sdc1[12](R) sdh1[10] sdb1[6] sdd1[7] sdg1[11] sde1[9] sdf1[8]
7814049792 blocks super 1.2 level 6, 256k chunk, algorithm 2 [6/6] [UUUUUU]
[>………………..] recovery = 0.2% (5791552/1953512448) finish=356.1min speed=91156K/secーー Disk to Diskのコピーなのでリビルド(69734K/sec)に比べて明らかに転送速度が速くなっています。ーー
unused devices: <none>
(3)悪いディスクを取り除く
(2)が正常に完了すると問題のあったパーティションはRAIDから自動的に削除されます。そのため特に何か特別な操作は必要ありません。サーバーをシャットダウンしてディスクを物理的に切り離すだけです。

右が交換用に購入したST4000DM004。左が交換するために取り出されたST3000DM002。技術の進歩で60%ぐらいの厚さになっている。
こうやって記事にすると大変そうに見えますが、実際はそれほどではありません。一度やり方を確立すれば後はそれを繰り返すだけです。
所要時間は3TBのディスクでは以下のような具合です。
リビルド : 11時間程度
コピー : 9時間程度
私の周辺(ITエンジニア)でも自作PCにSoft RAIDを使っている人は皆無です。私としては柔軟性あり、耐障害性あり、コストも安いと3拍子そろっているのでオススメなのですが誰も耳を傾けてくれません。
NAS用ディスクとは24時間x365前提でMTBFを算出したものでWestern Digitalの赤いラベルのものが有名です。インプレスが(たくさん広告料をもらっているのか)一時期ものすごく推していました。私も今回の障害を機に調べてみました。
| メーカー | 型名 | NAS用 | MTBF | ロード/アンロード サイクル | 製品保証 | 価格(アマゾン調べ) |
|---|---|---|---|---|---|---|
| Western Digital | WD40EFRX | ○ | 1,000,000 | 600,000 | 3年 | 14895 |
| Western Digital | WD40EZRZ | ☓ | 記載なし | 300,000 | 2年 | 7903 |
| Seagate | ST4000VN008 | ○ | 1,000,000 | 600,000 | 3年 | 12977 |
| Seagate | ST4000DM004 | X | 記載なし | 600,000 | 2年 | 7850 |
NAS用のディスクと普通のディスクの違いは極論するとMTBFの記載の有無、保証期間の長さにあると言えます。それでこの価格差です。せめて保証期間が通常版の2倍あればいいのですが1.5倍です。そのためどうしてもNAS用ディスクを購入する気にはなれません。特にWD RED(WD40EFRX)は私にはぼったくり価格にしか思えません。